




Hi! Hope you’re doing well. Let me walk you through what’s going on in my head when I need to explain “What is Data Engineering? And What has been going on with it recently?”.
Where do I start? And how to not kill an enthusiast or a friend with my tedious explanation? Should I start from the beginning of the time? Or should start from the beginning of all data? Although I did not live through all the eras of data I wander off onto a lot of things in the field while explaining it.
Introduction
After being in the data field for more than 4 years and witnessing two major industry shifts, I’m somewhat comfortable talking about my experience in Big Data era (Hadoop Ecosystem) and Modern Data Engineering (Spark on Databricks, Cloud and Data Modelling).
But, how does all of this can be contextualized by beginners and experienced folks? Be it for skills or where the industry is headed. A lot of buzzwords and fancy tools are thrown around without the right context IMO.
The Fundamentals of Data Engineering book provides the rightful context about Data Engineering (DE) from the past, the present and the future. Let’s dive in!
What is this book about?
The authors mentioned that they are recovering data scientists turned data engineers at the very beginning of the book. Much like the analytics industry, they started with Data Science stuff before moving into data engineering roles.
In this book, the fundamentals of data engineering are expressed in a less opinionated manner. Everything about the data platform/s, architectures, processes, tools and managed services is put into a context of the broader data engineering lifecycle without arguing which tool is better than the other.
The book also introduces some of the central ideas to the DE field like:
Architecture is a living entity within the data engineering lifecycle and evolves based on the requirements
Use standardized tools and services mostly and build custom tools and services for competitive advantage
The data maturity of an organization i.e., utilizing the data for business use cases; matters more than just having the latest and greatest tools in the data architecture
The Data Engineering team must collaborate with all the stakeholders from upstream systems to downstream data consumers to understand systems and automate the data serving
and many more…
Data Engineering Lifecycle
The bulk of the book covers the different phases within the Data Engineering Lifecycle. As stated in the book, the Data engineering lifecycle comprises stages that turn raw data ingredients into a useful end product, ready for consumption by analysts, data scientists, ML engineers, and others.
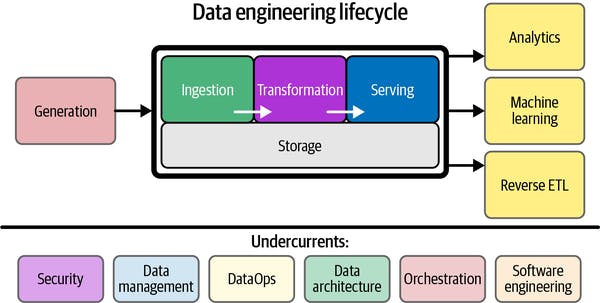
The stages of the data engineering lifecycle are as follows:
Generation - How the data is generated, type of the system, frequency of data generation etc.
Storage - How to store the generated data, choose the right data storage system etc.
Ingestion - Types of ingestion, frequency, ETL vs ELT, CDC etc.
Transformation - Transform the data to a required format, tools available for transformation, the role of SQL in data transformations and data modeling
Serving - Data served to different stakeholders, Reverse ETL etc.
While performing all the necessary activities to serve the data to the stakeholders, data engineering teams must also take care of the undercurrents like
Security - Security of the data at rest, while transmission and in some cases while processing
Data Management - How data is stored and exposed to various stakeholders
DataOps - data quality, governance, and security
Data Architecture - data architecture reflects the current and future state of data systems that support an organization’s long-term data needs and strategy
Orchestration - the central hub that coordinates workflows across various systems
Software Engineering - Coding and DevOps practices. Writing production-grade code and scaling backend systems for data applications
The authors mention a variety of tools for each topic in the data engineering lifecycle and explain their benefits and tradeoffs on a high level. This gives us enough context to understand the tools but one should go much deeper than what’s mentioned to understand them completely.
Future of Data Engineering
The data industry has seen a lot of small to large transformations thanks to managed services on the cloud. Batch processing, [ETL and ELT](aws.amazon.com/compare/the-difference-betwe..; have served the data industry well for a long time and it’s showing its age in recent times.
The next major transformation around the corner is near real-time data processing and serving. It is discussed at length in the book and offers a practical view of this trend.
One thing that doesn’t change for the foreseeable future in data engineering is the Data Engineering Lifecycle. It is fundamental to how the data is generated, stored, processed and served. It will still be relevant in the streaming era as well.
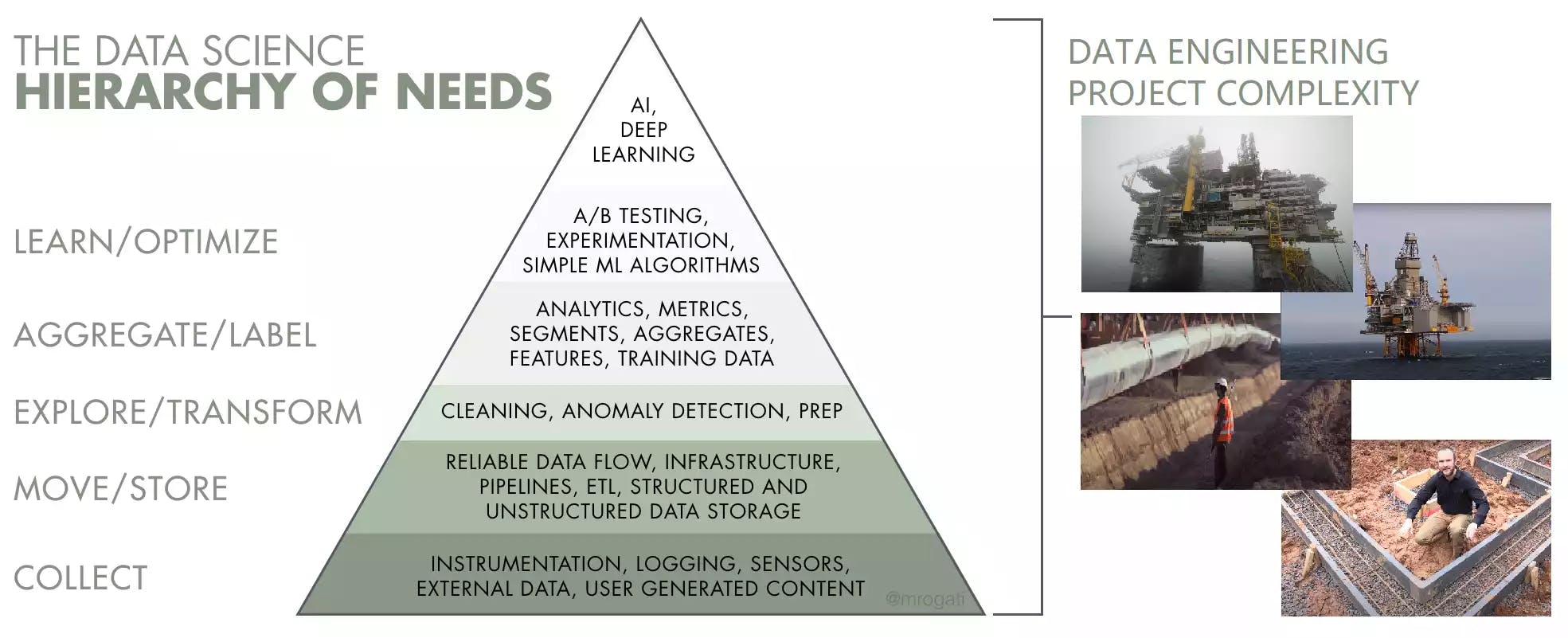
The below picture illustrates the essence and complexity of data processes.
The role of data engineers currently looks like the below picture. There is a lot of definitions for what a data engineer is and what they should do. I think it highly depends on the organization, team and who they are primarily serving the data to.
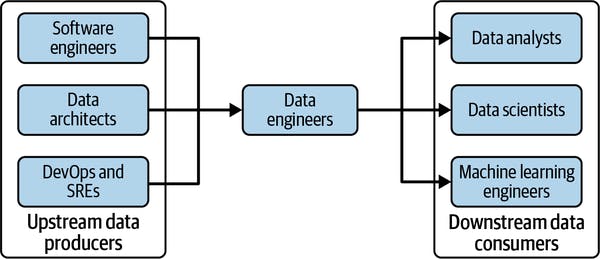
Expect the definitions and roles to change a bit as the industry finds new ways to produce and consume the data in the future
Who is this book for?
This book is for data engineers, of course; data professionals who would like to understand where the industry is headed.
This book offers a very broad view of the data engineering field. If you are an experienced professional who would like to go in-depth on certain topics, it's better to pick books or material specific to those topics.
Conclusion
If you’re a beginner or someone trying to understand what’s going on in the data engineering field, this book helps you contextualize a lot of jargon and trends in it well. You can expand your knowledge further on the relevant topics and in demand based on that.
Thanks,
Mani